
Frequency and Bias
An important consideration in any classification task is class frequency. Class imbalances are problematic because the classifier becomes less sensitive to the minority classes. Consider a training set with a majority class A and minority B. An algorithm trained on this imbalanced data will develop a bias toward predicting A just because it appears more often. Another dataset could in theory contain more of B, for example. This classifier would function poorly in this case because it learned a preference for A.
To avoid this bias, perform class balancing. There are different ways to accomplish balancing. One method is to oversample the minority classes by duplicating observations. However, oversampling can cause the algorithm to overfit, and the data becomes skewed toward the replicated observations. Alternatively, one could undersample the majority class, leading to a loss of valuable information for a classifier [1]. I prefer to maintain as much information as possible.
In this article, I explain variations of oversampling, including using existing observations from the minority to synthesise new data. Balancing via artificial means is known as Synthetic Minority Oversampling Technique, or SMOTE [3].
SMOTE and Tomek Links
A data point can be represented as a vector, where each entry of the vector is an attribute. SMOTE works by first selecting a feature vector from the minority class at random. Then, the algorithm chooses a random neighbouring feature vector from k-nearest (usually five) neighbours. The new, synthesised, feature vector lies at an arbitrary point along the line connecting the two [3]. Fig.1 depicts synthetic data generation in SMOTE with an example dataset.
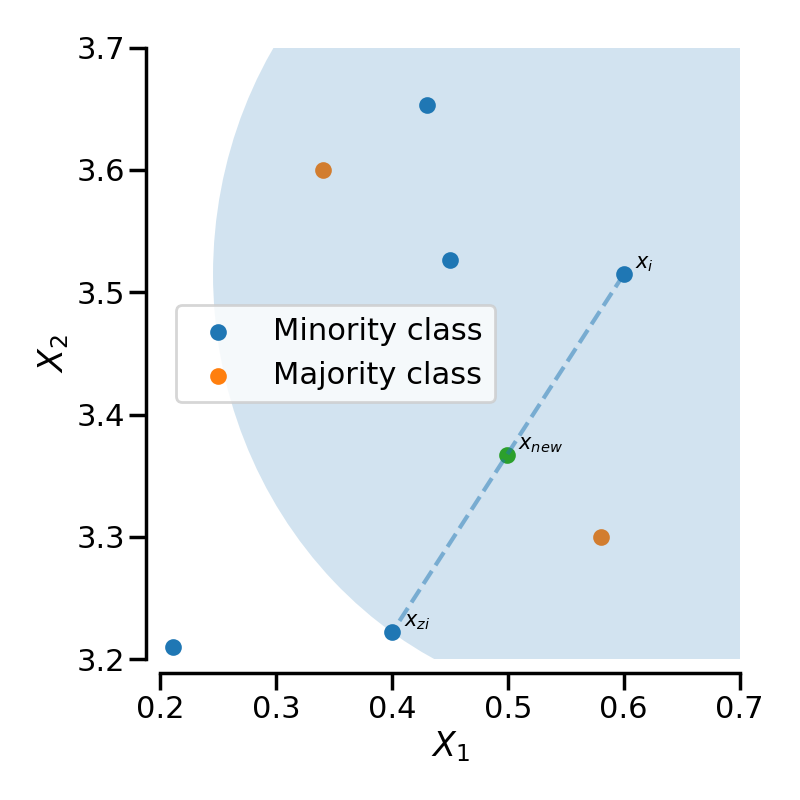
imblearn [2].The problem with SMOTE is that it can generate noise by interpolating points between outliers [2], and alone does not necessarily improve on the more straightforward random oversampling method. It is unlikely that SMOTE adds any additional information by using existing data, but SMOTE still shifts the bias toward the minority class [2]. Applying SMOTE may increase the sensitivity of the minority class but could decrease accuracy and precision. The authors of SMOTE found that combining SMOTE with under-sampling methods can improve classification performance [3].
To address some issues with SMOTE, particularly the case of synthetic noise, there is a modified version, SMOTE+Tomek, which tries to clean the feature space of synthetic noise. SMOTE+Tomek removes a majority class point with the nearest neighbour of another class. The pair of two closeby opposing types is called a Tomek link and is illustrated in Fig.2 [2].
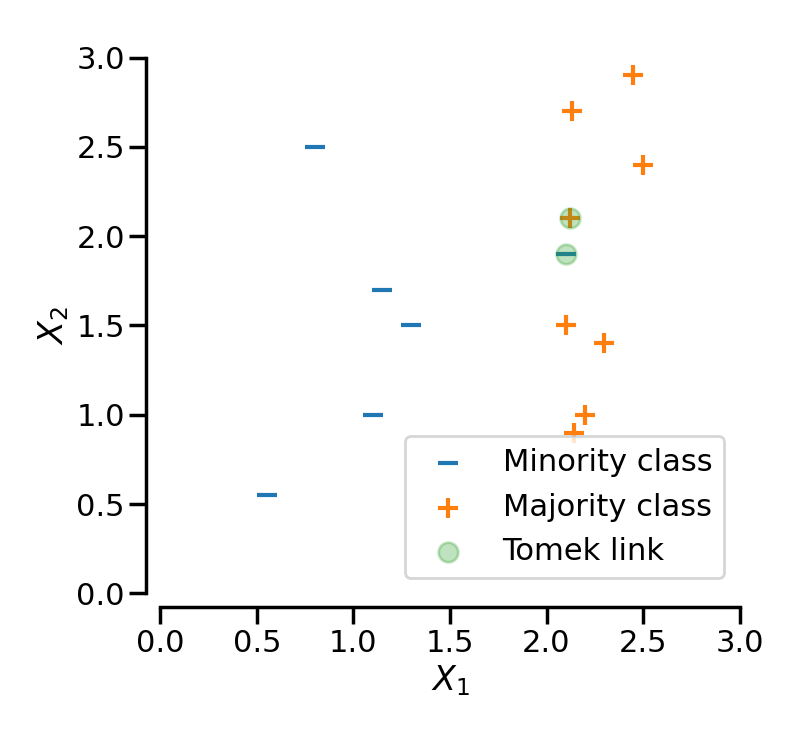
Undersampling the majority class with Tomek links thus removes boundary cases between classes and class label noise.
Another variation of SMOTE is SMOTE+ENN. Considered an improvement to removing Tomek links, SMOTE+ENN deletes the k-nearest neighbours as well as the points of the Tomek link [4]. There are more variations of SMOTE, including KMeans+SMOTE [5] which applies KMeans clustering before SMOTE.
It is important to note that class balancing is performed after the train-test split otherwise SMOTE will interpolate points between test data in training data. In this scenario, the new feature vectors in the training set could leak information about the location of points in the test data.
An alternative method to deal with imbalanced data and avoid SMOTE entirely is using balanced ensemble classifiers. In balanced ensemble methods, bootstrapping can be used to sample the data so that the constituent classifiers (e.g., trees in a forest) train on subsets with the classes present in equal amounts [6].
Example in Python: imblearn library
from imblearn.pipeline import make_pipeline
from sklearn.ensemble import RandomForestClassifier
from imblearn.over_sampling import SMOTE
pipeline = [SMOTE(random_state=0),
RandomForestClassifier(random_state=0, min_samples_split=4, n_estimators=500)
]
model = make_pipeline(*pipeline)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)See more on the imblearn website: https://imbalanced-learn.org/dev/references/generated/imblearn.over_sampling.SMOTE.html#
References:
[1] Ma Y, He H. Imbalanced learning: foundations, algorithms, and applications. John
Wiley & Sons; 2013
[2] imblearn library documentation; By the Imbalanced-learn developers. Available from:
https://imbalanced-learn.org/dev/index.html.
[3] Chawla NV, Bowyer KW, Hall LO, Kegelmeyer WP. SMOTE: synthetic minority over-
sampling technique. Journal of artificial intelligence research. 2002;16:321-57.
[4] Batista GE, Bazzan AL, Monard MC, et al. Balancing Training Data for Automated
Annotation of Keywords: a Case Study. In: WOB; 2003. p. 10-8.
[5] Last F, Douzas G, Bacao F. Oversampling for imbalanced learning based on k-means
and smote. arXiv preprint arXiv:171100837. 2017.
[6] Chen C, Liaw A, Breiman L, et al. Using random forest to learn imbalanced data. University of California, Berkeley. 2004;110(1-12):24.
d case studies. MIT Press; 2020.