My Samsung S9 is usable hardware. However, the Android version feels slow and is no longer supported by Samsung – i.e., it hasn’t received security updates since 2022. One option is to sell it and buy a new phone. Another option is to install a new operating system on it! Thereby reducing e-waste and saving money.
I can install a new OS for free on my S9, improving the phone’s longevity and giving it a fresh new look. Let me introduce /e/OS (“e OS”).
/e/OS is a modified version of Android, a custom ROM, that is maintained independently of Samsung or Google’s Android. /e/OS is also a fork of an operating system called LineageOS and removes almost all of the closed-source Google code from Android.
/e/OS is open-source Android at its core, with no Google apps or Google services accessing your personal data. So if privacy is important to you, /e/OS is a good option.
There are other custom ROMs out there but I find /e/OS to work well with most apps. It also looks clean and is easy to install with their Easy Installer app which walks you nicely through the process.
Is Privacy Traded for Functionality?
For most applications, /e/OS is great, but not all. The App Lounge is your Play Store/App Store but focuses on Privacy. I like how it scores an app’s privacy out of 10. I try to minimise the number of low privacy-scoring apps on my phone.
The App Lounge has pretty much all apps that you would want. I can get working Instagram and Discord – even if they are not the most privacy-respecting applications. However, it was hard to find Discord and some common apps were not readily findable. The App Lounge is also filled with some weird and random apps too but at least it doesn’t have ads all over like Google Play Store.
I find for messaging, most apps work fine except Facebook Messenger which didn’t work for me. One surprisingly great app is NewPipe, a client for YouTube. NewPipe gives you all the perks of YouTube Premium for free and doesn’t even track you as YouTube does. The consequence is that you are not provided with recommended content.
So /e/OS has me covered for YouTube and messaging. Navigation/maps, however, is a big trade-off (in my opinion).
The default maps app is Magic Earth. Magic Earth’s routing can be quite off, especially for the London Underground. It will recommend poor routes – I don’t really trust it. Google Maps is far superior as a service. I use TFL Go in tandem with Magic Earth when navigating London.
As for e-mail, I can use my Gmail account just fine, as well as my Murena e-mail that I got with my Murena cloud account (Murena is behind /e/OS). More on that later.
/e/OS has some advanced privacy features which I like. You can toggle on the use of the Tor network, and you can block Trackers on apps.
When using /e/OS, there is a small trade-off between functionality and privacy, but not in all aspects.

Murena Cloud
Your /e/OS phone has good (optional) integration with Murena Cloud. Part of the point of /e/OS is moving away from Google. Murena Cloud is an alternative to Google Cloud but with only 1GB free compared to Google’s 15GB of free space.
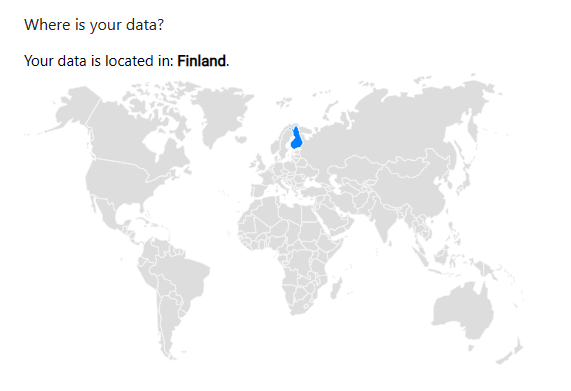
However, I like Murena’s transparency in telling me which country my data is being held. They also give you an e-mail alias if you don’t want to always give out your e-mail.
Closing
/e/OS looks good and works well for me (apart from Maps). /e/OS is not for everyone and I think it depends on the person – the advanced privacy features are probably not worth the small functionality trade-off for most people.
An S9 specific issue: I couldn’t find a way to map the Bixby button to anything. I would also like to have a cap on battery charging (cap at 85%) like my S21 has to prevent overcharging and increase battery longevity. Clearing all open tabs was also not obvious to me and should be more prominent. Another problem was enabling 2FA for Murena cloud but I managed it – this needs to be easier.
/e/OS has good privacy out of the box and most Meta and Google apps like Instagram, WhatsApp and Gmail still work – it’s good they’re there in case you still really need them. However, it almost defeats the point of the OS.
Overall a great OS and alternative to Google and Apple operating systems.